

Why businesses are starting with GenAI search.
Four LLM superpowers are unlocking insights and driving innovation.


A lot of enterprise knowledge is hiding in plain sight. Think of the rich data captured in “unstructured data”: PDFs, PowerPoint presentations, Word documents, images, charts, and even our communication systems (Slack, Teams, email, etc.). If we’re being honest, despite massive investment in the storage of “structured data” (databases, data lakes, business intelligence tools, etc.), much of the knowledge in this data is inaccessible as well.
This is a huge challenge for businesses, and innovation in particular. Christian Szegedy, an AI research scientist and co-founder of xAI, stated:
Just look at what science is about: finding more and more obscure connections between areas that are less and less obviously connected.
Many have come to believe a key to unlocking this hidden knowledge, finding these obscure connections, and, as a result, accelerating innovation is the creation of next generation enterprise search capabilities powered by GenAI. Most of these solutions are leveraging an approach called retrieval augmented generation (RAG), a specific type of GenAI enabled by large language models (LLMs). For the brave among you, I’ll dive into RAG more deeply in the Technology Wise feature below. First though, let’s discuss LLMs.
Four LLM superpowers.
Previously I wrote about the different types of AI. A specialized type of the deep learning models described there is the large language model, or LLM. LLMs are “very large deep learning models that are pre-trained on vast amounts of data”1 and are notable for their “ability to achieve general-purpose language generation and understanding.”2 Getting to know a little more about how LLMs work reveals their superpowers and, as importantly, their limitations.
Scale: LLMs are trained3 on an enormous volume of text to predict the next word (or “token”4) in a sequence. In the process of learning to predict efficiently and effectively, LLMs learn patterns and structures representing the vast array of human knowledge expressed in text across the Internet. The learned patterns and structures provide LLMs with a capability which can be thought of as a contextual understanding - an understanding of how things work, work together, and relate to one another - albeit one based on statistical relationships and dependencies rather than genuine comprehension. One of the surprising characteristics of LLMs, like the ones powering OpenAI’s ChatGPT and Meta’s Llama, is how well they scale to massive quantities of training data. Llama 3, for example, was trained on 15 trillion tokens, or approximately 12 trillion words of text. Bottom line: The scaling superpower provides LLMs with a very broad and deep contextual understanding, including an understanding of extremely rare patterns and structures.
Similarity: Traditional search technologies relied on keyword-based methods like inverted indexes, which were limited because they depend on exact term matching and could miss the semantic meaning of queries. In 2013, Google introduced Word2Vec, an embedding5 model that produced vector (or numeric) representations of words, positioning similar words closer together. Embeddings became feasible for use in search applications recently due to advancements in computing power and the development of the transformer6 architecture in 2017. Transformers, which enabled modern LLMs, use a mechanism called self-attention7 to understand the relationships between words in much longer sequences, regardless of their position. Bottom line: This superpower enables more accurate and semantically relevant search results, making it easier to find specific information in vast datasets consisting of both structured data (like databases and spreadsheets) and unstructured data (such as PDFs, emails, and social media posts).
Summarization: LLMs excel at distilling large quantities of text into concise summaries. To some extent they learn this capability during training on next word prediction - an example of a learned pattern (or abstract concept). However, they can also be specifically trained in this skill. LLMs can be fine-tuned8 by exposing them to examples of text paired with a human- (or AI-) curated summary. These examples teach the LLM key aspects of great summarization, aligning their output with their user’s preferences. Bottom line: Whether inherent or fine-tuned, this superpower makes LLMs incredibly useful in business settings, where they can condense lengthy reports, research materials, and unstructured text into clear, actionable insights that enhance the decision-making process.
Synthesis: There’s no reason to believe the high-level abstractions created during LLM training are domain specific. Anthropic’s work on interpretability seems to support this idea. Think of something like the exponential function. It would be far more efficient for a model to learn and store a concept once, rather than once for bacterial growth and once for radioactive decay. As the LLM predicts the next word, it draws on these abstractions and, in the process, can produce outputs which apply them across domains in a way that might not be obvious to human thinkers. Bottom line: This superpower makes LLMs invaluable tools for brainstorming sessions, strategy development, and innovation workshops, where generating a broad range of ideas quickly can be crucial to success.
Two LLM limitations.
While LLMs have amazing superpowers, new technologies rarely come without caveats. Let’s look at two key limitations of LLMs.
Hallucinations: It’s important to remember that LLMs are not information/fact retrieval systems; they are pattern and structure detectors that predict (or “guess”) the next best word in a sequence. Imagine an LLM is happily going along predicting the next word and it comes to a situation where the patterns and structures it learned during training for a context were weak, likely caused by limited occurrences in the training data. It will select the highest probability word, but there is no guarantee it is the correct word. Building on this incorrect word it continues selecting words with great confidence which are plausible but nonfactual given the original context. Researchers call these fabrications “hallucinations”9. LLMs can generate incorrect dates, numbers, names, web sites, and quotations. A partial solution for hallucinations is the RAG architecture I describe below, but this characteristic is not always negative or a limitation. Human creativity often appears like an out of bounds prediction at first. Many uses of LLMs outside of business (such as writing poetry, songs, fiction, etc.) and some uses within business (such as the cross-domain synthesis we discussed earlier) benefit from hallucinations. The key for business leaders is to understand they occur, and architect systems in ways which minimize hallucination risks and instead leverage their creative and innovative aspects.
Safety and Security: As powerful as LLMs are, they come with significant safety and security concerns. One major issue is bias. LLMs can unintentionally learn and propagate biases present in their training data, leading to outputs that reinforce stereotypes or discrimination. This can have serious societal impacts, from spreading misinformation to influencing hiring decisions unfairly. To minimize biases, it's important to use diverse and representative training data and implement bias detection and correction mechanisms. Security is another critical concern. LLMs can inadvertently expose personally identifiable information (PII) or protected health information (PHI), posing risks to individual privacy. Additionally, they might misuse or leak intellectual property. Implementing strict data handling protocols and access controls helps safeguard against these risks. Recognizing and addressing these safety and security issues helps businesses harness the power of LLMs safely, responsibly, and effectively.
Balancing superpowers and limitations unlocks innovation.
Large language models offer businesses breakthrough capabilities in scale, similarity, summarization, and synthesis, unlocking hidden insights and driving innovation. However, it's important to be aware of their limitations, such as hallucinations and the potential for biases and security risks. By understanding and mitigating these challenges, businesses can effectively leverage LLMs to transform vast amounts of data into actionable intelligence, while minimizing the risk of hallucinations, maintaining ethical standards, and ensuring regulatory compliance.
As always, the quick section below will dive deeper into the technology, so keep reading but only if you want to geek out!

One of the most widely adopted approaches to minimizing LLM hallucinations and increasing the groundedness of their generated responses is retrieval augmented generation (RAG). RAG is a method that combines the strengths of information retrieval and LLM text generation. In addition to hallucinations caused by limited exposure to concepts in their training data, RAG addresses two other important LLM limitations. First, LLMs are trained using data as of a certain point in time. Unless the model is further trained, its parametric knowledge stops as of this date and it will be unaware of events subsequent to this point in time. Second, LLMs are trained on data freely available on the Internet. Data which is proprietary to an organization will (hopefully!) not be held in the model’s parameters. Let’s walk through how RAG addresses these limitations.
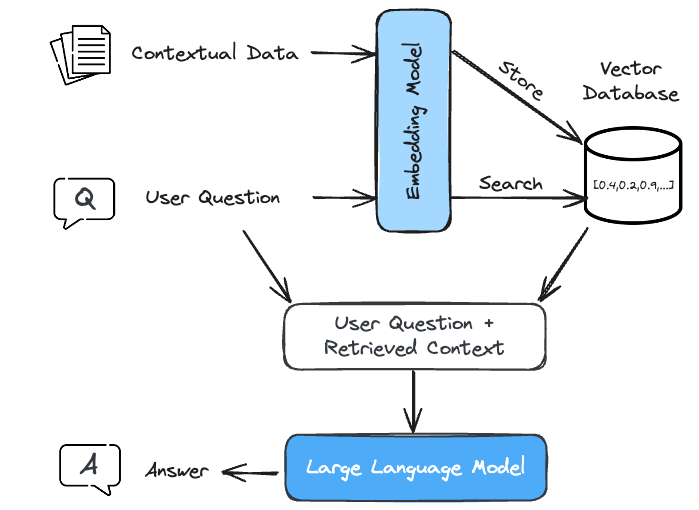
First, contextual data is transformed into dense, low-dimensional vectors using an embedding model and stored in a specialized vector database. Think of this as taking the information the user wants to complement the model’s knowledge with (be it timely text, a PDF, an Excel sheet, etc.), transforming it into a purely numeric representation, and storing it for semantic search later.
Next, the user asks a question which is passed through an embedding model to create its vector representation. This vector is compared against all stored vectors in the database using metrics such as cosine similarity10. This determines how close or far the vectors are from each other in the vector space, effectively identifying the most relevant documents.
Finally, both the user’s question and the retrieved documents are fed into a language model, which uses the context and knowledge from the documents to generate a detailed and (hopefully!) accurate response. This process helps ensure that the generated answer is grounded in real, up-to-date information, making it more reliable and informative.
Let me hear your “natural language”.
What questions, criticisms, or suggestions do you have? Where would you like me to go from here? Please feel free to engage with me and the rest of the community in the comments below.
Postscript.
What are Large Language Models? on Amazon Web Services
Large Language Model on Wikipedia
Unsupervised Learning on Wikipedia
What are tokens and how to count them? on OpenAI
Word Embedding on Wikipedia
Transformer on Wikipedia
Attention is All You Need on arxiv
Fine Tuning on Wikipedia
Hallucination on Wikipedia
Cosine Similarity on Wikipedia